
Historie
Automatické rozpoznávání řeči (dále jen ASR - Automatic Speech Recognition) je "staré" tak, jak je dlouhá existence počítačů. Na počátku se jednalo o značně primitivní systémy. Dokázaly rozpoznat pouze několik izolovaných slov a fungovaly na principu porovnávání nahrávek slov (referenční v paměti počítače versus právě vyslovené slovo). Systém byl také závislý na řečníkovi, pokud začal "diktovat" jiný řečník, úspěšnost se rapidně zhoršila. S postupem doby rostla pracovní a paměťová kapacita výpočetní techniky, ale také síla matematického aparátu používaná v rozpoznávači. ASR systémy se postupně naučily rozpoznávat až několik miliónů slov. Jsou nejen schopny být nezávislé na mluvčím, ale také se na něj umí během rozpoznávání adaptovat. Další směr pokroku byl v "plynulosti rozpoznávané řeči". Od diktování izolovaných slov jsme se dostali k rozpoznávání plynulé spontánní řeči plné různých výplňkových slov a zvuků vydávaných při zaváhání. Oproti minulosti, lze současné systémy považovat také za rozumě robustní vůči okolním šumům a ruchům.
Na ASR se pracuje už přes 50 let. Svého času, tuším, že Gates sliboval plně funkční ovládání PC hlasem v roce 2000. Viditelné "pokroky" se objevují až v posledních letech (zejména díky Googlu). Ve vědecké komunitě panuje názor, že problematika ASR se bude řešit ještě minimálně 20 let (k dosažení úspěšnosti srovnatelné s člověkem).
Jak to funguje
Celé ASR se snaží kopírovat rozpoznávání tak, jak funguje u nás, lidí. Rozpoznávání řeči u člověka studuje několik oborů. Například obor psycho-akustika, která se snaží zjistit, co se děje v uchu a v centrech sluchu na "nízké úrovni". Na druhou stranu obor lingvistiky zkoumá jednotlivá slova a jazyk jako celek. Díky psycho-akustickým výzkumům máme třeba ztrátový formát MP3 pro uchovávání hudby. Stále však počítače rozpoznávané řeči "nerozumí". Umí ji sice přepsat do textu, ale informace v ní obsažená jim uniká. Porozumění obsahu řeči (ale i psaného textu) se však zabývá už jiný vědní obor.
Akustický model
Řeč je ve své fyzikální podobě spojitá funkce změny akustického tlaku (to uvidíme, když si zobrazíme audio nahrávku v nějakém editoru). Člověk však "neslyší" změnu akustického tlaku, ale tóny (frekvenci signálu). To se děje ve vnitřním uchu - kochlei. Ta převádí časovou realizaci signálu do frekvenční. Frekvenční spektrum se pak dále posílá do mozku. V ASR máme podobné zařízení, kterému říkáme "extrakce příznaků". Ta obsahuje Fourierovu transformaci, model pro parametrický popis obálky spektra a nějaké dekorelační techniky. Výstupem je 13 příznaků (reálných čísel) každých 10 ms. Ty se ještě rozšíří o rychlostní a akcelerační (delta a double delta) parametry. Výsledek je tedy celkem 39 příznaků, a to je vstupem do akustického modelu.
Po lingvistické stránce je každý jazyk složen ze základních zvukových jednotek - fonémů (čeština cca 40, angličtina cca 45). Čeština je v tomto pohledu jednoduchá, protože se jedná o tzv fonetický jazyk. V češtině odpovídají fonémy písmenům (až na pár výjimek jako je "mě -> mňe", "vě -> vje“…). Angličtina je v tomto složitější, protože tam se "jinak čte a jinak píše".
Ale zpět k fonémům. Akustický model se snaží naučit, jak který foném zní. Přesněji, jak foném "vypadá" v podobě sekvence příznaků. Aby se toto mohl naučit, potřebuje řečová data, kde je popsáno, který "zvuk" je který foném (těmto datům říkáme anotovaná data). Lidský mozek, je v tomto dokonalejší, protože si tuto informaci v raném dětství odvodí sám. Aby ASR systém byl přesnější, pracuje s tzv. kontextově závislými fonémy. Nemá tedy pouze jeden model pro foném "a", ale má modely pro foném "a" v kontextu "x-a-y", kde "x" je předcházející foném a "y" je následující foném. Je to proto, že kontext ovlivňuje výslovnost daného fonému.
Pokud máme anotovaná data a sadu fonémů, můžeme vytvořit statistický model, který nám bude říkat, jak asi vypadá matice příznaků jednotlivých fonémů. Tento model obsahuje tzv skryté Markovovy modely. Model každého fonému má tři stavy (začátek, střed, konec), modeluje se tím "časový vývoj" fonému. Každý stav pak obsahuje gaussian mixture model. Je to směs gausovek (gausova křivka - normální rozložení - zvonová křivka), která modeluje rozložení příznaků.
Jazykový model
Druhá důležitá část ASR je jazykový model. Každý jazyk má svá pravidla - gramatiku. Ovšem zabudování takové gramatiky (často plné výjimek) do rozpoznávače je komplikované. Mimo to, pro hovorovou řeč často gramatika neplatí. V ASR se tento problém řeší opět statisticky. Jednoduše se posbírají statistiky výskytů dvojic nebo trojic slov. Z těchto statistik se potom vytvoří jazykový model, který modeluje pravděpodobnost výskytu posloupnosti slov. Podobně to funguje i u člověka. Ve škole se sice učíme gramatiku, ale tak nějak rozumě mluvit umíme ještě v předškolním věku. To je tím, že jsme v dětství „naposlouchali“ statistiku, s jakou přicházejí "nová" slova na základě právě vyslovených slov. V praxi si necháváme v jazykovém modelu jen pravděpodobné dvojice či trojice slov. Za předpokladu 1 milionu slov, by všech trojic slov bylo 10^18, což je mimo současné možnosti techniky.
Jako poslední součást ASR systému je výslovnostní slovník. Ten přiřadí každému slovu výslovnost (posloupnost fonémů) a propojí tak jazykový model s akustickým modelem.
Pro rozpoznávání se z jazykového modelu, slovníku a akustického modelu vytvoří tzv. rozpoznávací síť. Je to obrovský orientovaný graf, kde jednotlivé stavy mají přiřazeny směsice gausovek. Místy se v rozpoznávací síti vyskytují i speciální "slovní" uzly, které říkají, že se má na výstup vypsat slovo (třeba "ahoj"). Tato síť se načte do speciálního programu (tzv. dekodéru). Vstupní nahrávka (ta která se má přepsat na text) se převede na matici příznaků, a také se vloží do dekodéru. Pak se spustí algoritmus rozpoznávání (tzv. token passing). Cílem je najít pro zadanou matici příznaků nejpravděpodobnější cestu grafem (rozpoznávací sítí). Po nalezení nejlepší cesty, se zjistí sekvence slovních uzlů, které leží na této cestě. Tato sekvence je výstup rozpoznávače - tedy text, který byl rozpoznán a měl by být řečen ve vstupní nahrávce.
Několik zajímavostí
Dobré anglické rozpoznávače obsahují cca 50 tisíc slov. Náš ASR pro češtinu obsahuje 1 milion slov. V češtině není problém se dostat na 3-4 miliony spisovných slov (kvůli morfologii).
Jak asi pozornému čtenáři dojde, slovo, které není ve slovníku, ASR nerozpozná. ASR však vždy něco vypsat musí. Záleží na vyvážení mezi akustickým a jazykovým modelem. Pokud by měl jazykový model příliš velkou váhu, bude v takovém případě vypsána pravděpodobná sekvence slov (i když nebudou z většího kontextu dávat smysl). V případě velké váhy akustického modelu, bude chybějící slovo nahrazeno sekvencí slov, která se akusticky co nejvíce podobají řečenému slovu. V současné době je jedna z oblastí výzkumu ASR vypořádání se s chybějícími slovy. Ta se pak rozpoznávají jako sekvence nějakých podslovních jednotek (třeba slabiky) a zpětně se z nich "syntetizuje" psaná forma slova. Pro češtinu to může být triviální (z důvodu fonetického jazyka), pro angličtinu to už je problém.
Náš ASR systém se automaticky adaptuje na řečníka a okolní šum. Toto se děje po cca 60s blocích. Adaptace na řečníka nebo šum zvyšuje úspěšnost rozpoznávání a robustnost systému.
Příklad: Pokud jste byli někdy na mezinárodní konferenci, možná se Vám stalo, že začal prezentovat nějaký student z Číny. Prvních 20 sekund jste neměli ponětí, co vlastně říká a vypadalo to, že mluví čínsky. Pak jste náhodou porozuměli 2 slovům, která byla anglicky. Váš mozek se najednou začal adaptovat. Pomocí těch dvou anglických slov, kterým jste rozuměli, dokázal porozumět dalším slovům a tak postupně adaptoval vaší "českou" angličtinu na "čínskou" angličtinu. Během minuty jste zjistili, že už studentovi a jeho "angličtině" rozumíte (i když na začátku byste na 100 % řekli, že to je čínština).
Systém je trénován na přibližně 200 hodin anotovaných dat z různých domén (konverzační řeč, čtená řeč, rozhlasová řeč,…). Pro angličtinu jsou rekordy v množství tréninkových dat v řádu jednotek tisíců hodin. Tvorba takovýchto dat je velmi časově náročná a drahá. V budoucnu určitě na řadu přijdou techniky trénování ASR, které nebudou potřebovat anotovaná data. Budou se tedy zdokonalovat podobně jako člověk. Anotovaná data budou potřeba pouze pro prvotní inicializaci ASR systému. Podobně jako u člověka. Pokud se budete chtít učit cizí jazyk tak, že ihned pojedete do cizí země, budete ztraceni a ničemu nebudete rozumět. Lepší je věnovat studiu daného jazyka několik měsíců v jazykové škole. Posléze, během vašeho pobytu, budete mít již ponětí o místním jazyce a váš "statistický model" v mozku bude mít na čem stavět. Mimochodem zkuste si spočítat, kolik hodin anglické řeči jste museli poslouchat, abyste se dostali na úspěšnost rozpoznávání cca 75 % (a to jste se učili také gramatická pravidla).
Úspěšnost rozpoznávání na množství tréninkových dat závisí nelineárně. Pokud například zvýšíme množství tréninkových dat o řád, sníží se chybovost například o "30 %" relativně.
Styl mluvení (čtená řeč, diktování, televizní zprávy, přednáška, běžná neformální konverzace,...) má velký vliv na rozpoznávání. Důvod je hlavě ten, že rozpoznávač rozpoznává dobře takovou řeč, kterou "viděl" při trénování. Pokud trénujete rozpoznávač pro přepis televizních zpráv, bude dobře přepisovat televizní zprávy. Když mu dáte rozpoznat neformální konverzaci, budou to data, která nikdy neviděl a tak bude úspěšnost horší. Totéž bude platit i obráceně. Problém není jen v akustickém modelu (to se dá částečně napravit adaptacemi), ale hlavně v jazykovém modelu (a slovníku). Pro konkrétní nasazení rozpoznávače, je vždy vhodné přizpůsobit jazykový model (přetrénovat) na cílové doméně.
Obr. 1
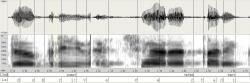
„Úryvek“ záznamu z editoru zvukových nahrávek. X-ová osa je čas (na příkladu cca 1 s)
V horní části je signál v jeho "surové formě" – výstup z mikrofonu. Takto se řeč zaznamená v počítači. Jedná se o digitalizované (tedy převedené na čísla) hodnoty změny akustického tlaku.
Vysvětlení:
Pokud hodíte kámen do vody a v nějakém bodě měříte změnu výšky hladiny, dostanete sinusovku. Pokud mluví člověk, jde o spojitý proces (který se v mikrofonu převádí na spojitou změnu nějaké elektrické veličiny - například napětí). V počítači se to převede v analogově-digitálním (A/D) převodníku do číselné podoby. Rozsah je uveden vlevo: -16240 až +18660. Signál musí být i časově vzorkovaný - máme například 8000 vzorků (čísel) za vteřinu. S tím tedy počítač pracuje, to počítač "slyší".
Snahou i u „jazykové výuky“ počítačů je kopírovat lidský sluch. A lidé slyší frekvence. Spektrum signálu zobrazuje druhá část obrázku (zhruba prostřední). Osa s rozsahem od 0 do 4 kHz je vlevo. Čím černější je barva, tím více je daná frekvence (tón) zastoupena (tj. je hlasitější). Něco podobného vzniká ve vnitřním uchu a putuje do mozku.
Spodní dva proužky reprezentují časově zarovnaný přepis. Uvedený příklad obsahuje slova "Dobrý večer tady " (následovalo nějaké jméno).
Slovní přepis, který nemusí být časově zarovnaný, ale musí být přesný (nesmí chybět slova), se používá při trénování. (viz dále)
Zcela spodní proužek obsahuje fonetický přepis. Jednotlivé symboly jsou fonémy, tedy základní zvuky jazyka. i: značí dlouhé i, C značí č,… Jedná se o naši interní definici, protože se většině lidí dobře čte. Standard ale vypadá například takto.
Trénování:
Pokud máme nahrávky, jejich doslovný přepis a výslovnostní slovník, lze spustit algoritmus, který natrénuje modely fonémů. Tento algoritmus postupuje tak, že na začátku ze slovního přepisu vytvoří fonetický přepis (tak jak je dolní proužek). Pouze jsou hranice fonémů rozmístěny rovnoměrně (pravidelně), protože nevíme, kde vlastně jsou. Pak v iteracích (cyklech):
1) Každému fonému náleží určitá část signálu (a tedy i matice parametrů). Pro každý foném se z jeho jednotlivých realizací (výskytů v tréninkových datech) vytvoří pravděpodobnostní model, jak asi vypadá matice parametrů.
2) Fonetický přepis se znovu zarovná (hranice fonémů se posunou), protože již máme jakýsi model. A zase krok 1.
Toto se opakuje, dokud se hranice nějak mění. Až se vše ustálí, předpokládáme, že jsou modely natrénovány.
Obr. 2
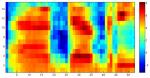
Příklad matice parametrů. Jedná se o 15 příznaků energie v kritických pásmech vždy po 10 ms. Jsou vypočteny pro první polovinu nahrávky, jako je na obrázku 1. "Energie v kritických pásmech" je spektrum, které zohledňuje poznatky z lidského vnímání zvuku (psychoakustiky).
Obr. 3
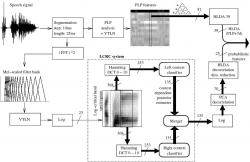
Tady je něco pro "gurmány". Takto se v state-of-the-art rozpoznávači řeči generují parametry (příznaky).
Vysvětlení zkratek/boxíků:
segmentace: signál se rozdělí na segmenty dlouhé 25 ms s posunem 10 ms (překrývají se tedy o 15 ms); FFT^2: energie spektra; filter bank: modelování citlivosti lidského sluchu (psycho akustika); VTLN: normalizace na délku vokálního traktu (tedy krku) - jedna z metod adaptace na řečníka; Log: logaritmus; LCRC systém: komplikovaná věc používající neuronové sítě, výstupem je matice pravděpodobností fonémů; PCA: Principal Component Analysis - matematická metoda, která dekoreluje hodnoty v matici příznaků (pootočí prostorem) a redukuje počet dimenzí; HLDA: heteroscedastic LDA (Linear discriminant analysis) - "něco jako PCA" - také redukuje počet dimenzí; PLP: příznaky postavené na psychoakustických vztazích a frekvenčním spektru; delty, double delty, triple delty: opět redukce dimenzí spojených v jednu velkou matici, která je na obrázku 4.
Obr. 4

Toto je to, co ve skutečnosti „leze“ do rozpoznávače. Pro každých 10 ms se jedná o 64 dimenzionální vektor (jestli je někde v textu uvedeno 39, tak se jedná pouze o PLP větev (ta horní). S ní rozpoznávání funguje také dobře, ale spolu s tou spodní je samozřejmě kvalitnější.
Pravděpodobnostní model tedy obsahuje normální (Gaussovo) 64-rozměrové rozdělení (1 rozměrné je "zvonová" křivka, dvourozměrné znázorňuje „kopeček“,…)
Obr 5
Jak vypadá síť? Pro zjednodušení uvažujme fonémy (ne kontextově závislé fonémy, tak by to bylo o řád složitější). Toto je příklad, velmi hloupé sítě, protože je jen dopředná (nemá cyklus) a dovolí vám rozpoznat jen:
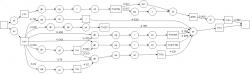
< s > THERE ARE < /s >
< s >I< /s >
< s > THEY < /s >
< s > THERE < /s >
< s > UH THERE < /s >
< s > THEY"RE < /s >
< s > UH THEY"RE < /s >
< s > UH THE < /s >
< s > THE < /s >
< s > OH THE < /s >
kde < s > znamená začátek promluvy, < /s > představuje konec.
Kulaté uzly jsou pravděpodobnostní modely fonému. Pokud uzlu dále nějakou část matice parametrů, vrátí vám věrohodnost, s jakou se mu ta matice „líbí“ (pokud ta matice representuje ten stejný foném jako je model, pak bude věrohodnost vysoká, pokud ne, bude nízká).
Hranaté uzly representují slova, která byla rozpoznána, tedy to, co se uživateli zobrazí na výstupu.
Případná čísla na hranách znamenají pravděpodobnosti jazykového modelu (tedy s jakou pravděpodobností právě tato dvě slova po sobě následují).
Taková sít se dá do dekodéru, kde je implementován algoritmus token passing (předávání příznaků). Do sítě se na začátku vloží token (prázdný půllitrák) a pak postupně putuje sítí. V každém modelu je do tokenu připočtena věrohodnost, s jakou model odpovídá právě zpracovávané části matice příznaků (přilévá se pivo do půllitráku). Pokud je více cest z uzlu ven, token se rozkopíruje (včetně obsahu). Pokud se srazí více tokenů v jednom uzlu, vyhrává ten lepší (plnější půllitr). Při průchodu slovem (čtvercovým uzlem) si token zapamatuje, kudy prošel. Až se zpracuje nahrávka (celá matice), jen se vybere přeživší token na konci sítě. Zjistí se cesta, kudy šel (seznam slov), a to se vypíše uživateli.
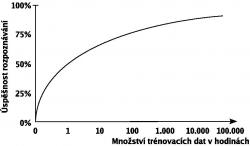
Obr. 6
Znázornění závislosti úspěšnosti na množství dat použitých k trénování.
Poznámka: většina know-how vzešla z výzkumu skupiny Speech@FIT na Fakultě informačních technologií VUT v Brně . Phonexia s.r.o. tento výzkum uvádí „do života“. Jde o plodnou spolupráci, která umožňuje „dotáhnout“ výsledky výzkumu do praxe. Přepis mluvené češtiny na mobilním telefonu lze vyzkoušet na této stránce.
Diskuze:


