Vývojáři z tajuplné laboratoře Google X lab v kalifornském Mountain View před třemi lety vyzobali z videí v YouTube 10 milionů obrázků a nakrmili jimi Google Brain (Googlí mozek) - neurální síť z tisíce počítačů naprogramovaných tak, aby zpracovávaly informace podobně, jako to dělají mimina. Po třech dnech koukání na opakující se vzory se Googlí mozek sám od sebe rozhodl, že umí poznat lidské tváře, lidská těla a ... kočky.

Zjištění Goole Brainu, že internet je plný kočičích videí, sklidilo záplavu novinářských posměšků, ale zároveň to byl milník na cestě ke zviditelnění „hloubkového učení“ (deep learning). Třicet let staré techniky, která umožňuje počítačům vyřešit zapeklité úkoly, které řeší lidé téměř inituitivně. Pomocí hrubé výpočetní síly a velkého objemu dat dokáží počítače rozpoznat tváře nebo porozumět mluvené řeči, aniž by předem věděly, s čím vlastně mají tu čest.
Technika hloubkového učení staví na ještě starším konceptu neurálních sítí volně inspirovaných mozkovými neurony s jejich hustým vzájemným propojením. Google Brain s milionem simulovaných neuronů a miliardou simulovaných propojení byl desetkrát větší než jakákoliv neurální síť před ním. Za jeho vybudováním stojí Andrew Ng ze Stanfordské univerzity v Kalifornii, který, kromě budování opět desetkrát většího systému s hlubokým učením, prosazuje myšlenku, že by přístup ke špičkovému vzdělání měl mít bez rozdílu každý. Můžete si tak díky projektu Coursera sami zkusit zjistit, jak to všechno funguje do nejmenšího detailu:
Tento úspěch, ve snaze naučit počítače myslet jako lidi, byl jako živá voda pro celé odvětví umělé inteligence, protože najednou stačí stroji předhodit libovolnou sadu dat a kategorizaci nechat na něm. Společnosti jako Google, Apple nebo IBM v poslední době agresivně skupují všechny nově se objevující společnosti zabývající se hloubkovým učením. Pro uživatele jejich aplikací to znamená lepší třídění fotek, porozumění mluveným příkazům nebo překlady z cizích jazyků. Pro vědce může hloubkové učení vyhledávat potenciální léčivé látky, mapovat propojení mozkových neuronů nebo předvídat funkci proteinů.
Odborníci z konkurenčního tábora tvrdí, že umělá inteligence se neobejde bez ručního vkládání pravidel, podle nichž se točí svět - například že „každá dívka je člověk“. Pokud je pak počítači předložen text zmiňující se o dívce, může si odvodit, že jde o osobu. V případě, že takových pravidel dáte dohromady opravdu hodně, může vám vyjít něco jako slavný vítěz soutěže „Riskuj“ Watson z dílny IBM z roku 2011.
Výše zmiňovaný Andrew Ng se v osmdesátých letech zabýval automatickým rozpoznáváním zobrazených objektů. Pokud ovšem máte ručně zadefinovat nějaký vzor, chce to hodně času a znalosti experta. Tehdy se hloubkové učení nabízelo jako jedno z možných řešení.

Neurální síť při hloubkovém učení pracuje s vrstvami poznání s postupně narůstající složitostí. Při rozpoznávání obličejů si například nejprve všimne všech těch pixelů v různých odstínech šedi: |
|

Další úroveň pak ze vzorů pro jednoduché tvary odvodí vzory pro komplexnější tvary a objekty, jako jsou nosy nebo oči: |

Zkombinováním těchto vzorů si pak některá následná úroveň uvědomí, že kouká na obličeje. |

První programy s hloubkovým učením neposkytovaly o nic lepší výsledky než jednodušší ručně definované systémy. V těchto dávných dobách ovšem ještě nepanovaly příznivé podmínky pro vznik skutečně výkonných neurálních sítí a navíc práce s nimi byla a je náročná, takže použitelných aplikací vzniklo do roku 2000 jen pár.
Historicky bylo ruční biflování umělých inteligencí nezbytné, protože neexistoval dostatečný objem elektronických dat pro tréning a výpočetní kapacita byla drahým a nedostatkovým zbožím. Tato situace se ale začala kolem roku 2000 obracet a internet se stal nevyčerpatelnou zásobárnou testovacích dat. Tehdy také začínaly růst výpočetní kapacity dostupné univerzitám, takže podle pionýrů hloubkového učení, mezi něž patří Yann LeCun z Univerzity v New Yorku nebo jeho tehdejší mentor Geoffrey Hinton z Univerzity v Torontu, nastal čas ukázat světu, co neurální sítě dovedou.

Od té doby zaznamenalo hloubkové učení mnoho zářezů na pažbě v soubojích s konvenčně programovanými protivníky. V roce 2009 například systém pro rozpoznávání řeči s hloubkovým učením překonal dosavadní rekord v přesnosti převodu mluveného slova do textu.

V renomované soutěži ImageNet Challenge porazil v roce 2012 všechny soupeře na hlavu Geoffrey Hinton se svým týmem, kteří se tehdy v soutěži jako první objevili s hloubkovým učením. V roce 2013 už pracoval s hloubkovým učením každý soutěžící.
V roce 2012 vypsala farmaceutická společnost Merck cenu pro toho, kdo překoná jejich nejlepší programy pro předpověď vhodných kandidátů pro léčiva, kteou vyhrál student Geoffreye Hintona George Dahl , když se systémem pro hloubkové učení vylepšil skóre Mercku o 15 %.
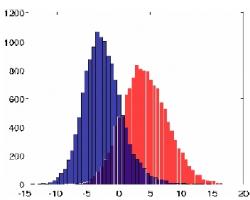
Začne to histogramem tváří (červeně) a ne-tváří... (Kredit: Quoc V. Le a kol., Arxiv) |

... a zakrátko jsme pro neuronovou síť zidealizovaný „zglajchšaltovaný xicht“. (Kredit: Quoc V. Le a kol., Arxiv) |
V současné době využívají hloubkové učení systémy Googlu, Microsoftu a dalších IT obrů. Je na něm postavená například i digitální asistentka Siri známá uživatelům iPhonů.
Hloubkové učení je velice dobré v rozpoznávání různých vzorů a má tu příjemnou vlastnost, že čím více ho krmíte, tím lepší dává výsledky. Až budoucnost ukáže, jestli se umělá inteligence bude ubírat pouze tímto směrem, nebo nějakou cestou využívající i tradiční zadávání pravidel, ale bez hloubkového učení to už asi nepůjde.
Každopádně pro studenty informatiky je to nyní velmi perspektivní obor. Kdo na tuto vlnu již nasedl nebo se do ní právě vrhá, nebude mít o pracovní nabídky nouzi.
Zdroj:
http://www.nature.com/news/computer-science-the-learning-machines-1.14481
Diskuze:


