Všichni dnes, zdá se, propadli kouzlu velkých jazykových modelů. Chrlí texty, generují kód, někteří tvrdí, že i obrázky, a vedou s námi konverzace, které by leckterý politik po čtvrtém pivu mohl závidět. Tvrdí se, že rozumí světu. Ale jak je to s jejich takzvanou „pamětí“? Člověk by řekl, že to nebude tak přímočaré. Kdo z nás ostatně nezažil tu komickou, či spíše tragikomickou situaci, kdy si umělá inteligence zapamatovala naprostý nesmysl, zatímco klíčovou informaci z předchozí věty s elegancí sobě vlastní ignorovala? Dosavadní pohledy na věc navíc, jak už to bývá, klouzaly po povrchu, zaměřovaly se na líbivé aplikace, nikoli na fundamentální mechanismy. Přiznejme si, občas má člověk pocit, že i jeho vlastní paměť by zasloužila důkladnou revizi, natož ta křemíková, chladná a bezcitná.
Problém se starým chápáním paměti, jestli nějaké vůbec bylo
Dosavadní studie, ty které se vůbec obtěžovaly něco studovat, se často zabývaly tím, co si umělá inteligence pamatuje, nebo k čemu tu svou paměť vlastně používá – typicky u takzvaných agentů, kteří by si měli pamatovat minulé interakce. Fascinující, nepochybně, ale připomíná to situaci, kdy obdivujeme fasádu honosné budovy, aniž bychom měli nejmenší tušení, jak vlastně drží pohromadě její základy. Chyběl jakýkoli systematický pohled na ty nejmenší, „atomické“ operace, které tvoří dynamiku paměti. Bez pochopení těchto základních stavebních kamenů je obtížné porozumět, jak komplexní systémy jako LLM agenti skutečně fungují. A ještě obtížnější, ne-li nemožné, je pak stavět robustnější a efektivnější modely. Je to trochu jako snažit se sestavit švédský nábytek bez návodu – výsledek může být, řekněme, překvapivý, a ne vždy v pozitivním slova smyslu. Kolikrát jsme jen kroutili hlavou nad tím, proč se ta věc chová tak, jak se chová? A kolikrát ještě budeme?
Nový rámec: Taxonomie a operace pro další století marnosti?
Tým výzkumníků, tentokrát z Čínské univerzity v Hongkongu, Univerzity v Edinburghu, jakési HKUST a, jak jinak, Huawei, přichází s novým, údajně strukturovaným pohledem. Navrhují rozdělit reprezentace paměti v umělé inteligenci do tří hlavních kategorií, což samo o sobě nezní nijak převratně, ale budiž:
- Parametrická paměť: Znalosti zakódované přímo do parametrů modelu, tedy vah neuronové sítě. Něco jako naše podvědomé vědění nebo naučené dovednosti, pokud tedy něco takového u strojů existuje.
- Kontextová strukturovaná paměť: Informace uložené v externí, organizované formě, například v databázi nebo znalostním grafu. Představte si pečlivě vedený deník nebo obsáhlou kartotéku plnou nepodstatných detailů.
- Kontextová nestrukturovaná paměť: Informace poskytnuté jako součást kontextu, typicky ve formě syrového textu – dlouhý prompt, historie konverzace. Ty lístečky s poznámkami, co máme všichni rozházené po stole a nikdy je nenajdeme, když je potřebujeme.
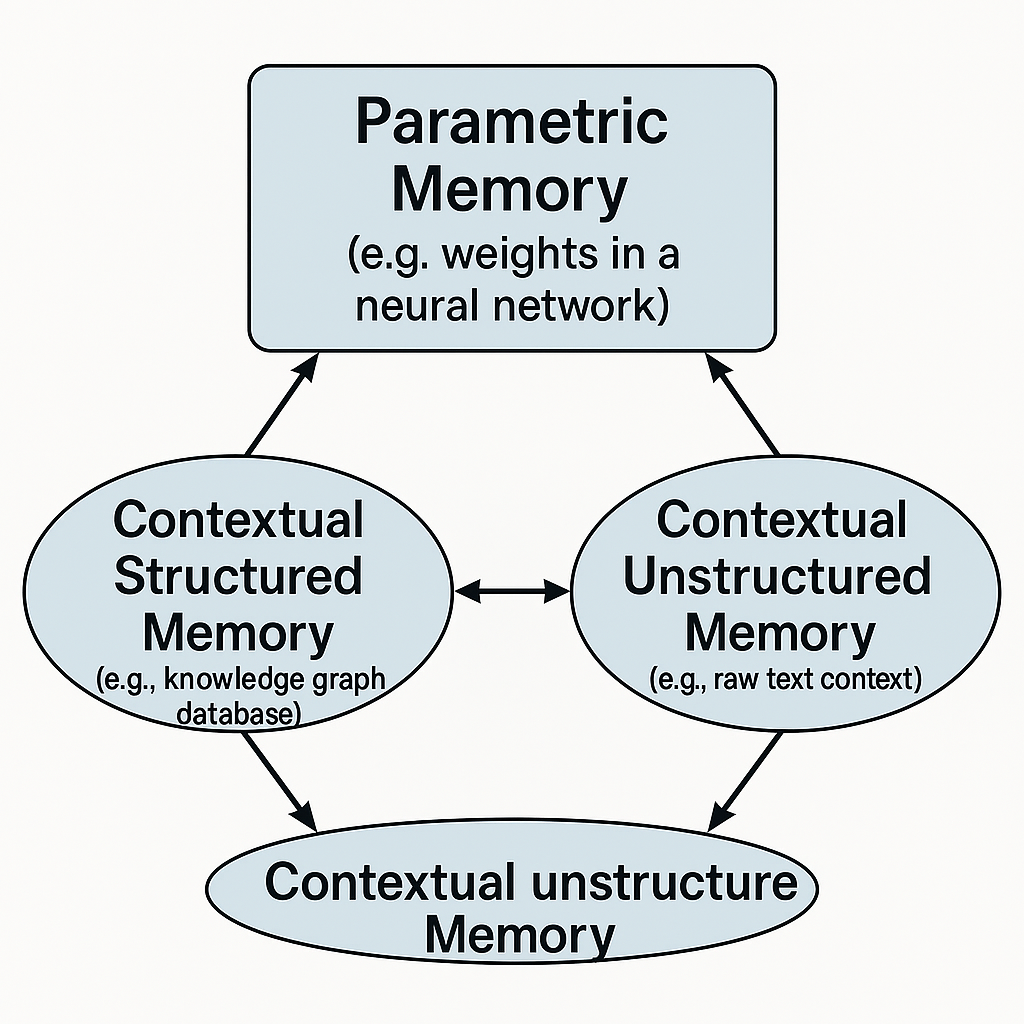
Schematické znázornění tří typů paměti v AI – parametrické (váhy v neuronové síti), kontextově strukturované (znalostní graf/databáze) a kontextově nestrukturované (surový textový kontext) – jako vzájemně propojené, avšak odlišné komponenty, možná jako oblasti mozku nebo datové struktury, jak si to představuje nějaký generátor obrázků. Zdroj: Vytvořeno AI
Klíčovým přínosem studie, alespoň podle jejích autorů, je pak definice šesti základních, takzvaně atomických operací, které s těmito typy paměti pracují:
- Konsolidace (Consolidation): Integrace nových informací do dlouhodobé paměti. Proces, při kterém se zážitky, pokud stroje nějaké mají, mění ve vzpomínky.
- Aktualizace (Updating): Modifikace existujících paměťových záznamů na základě nových dat. Protože i umělá inteligence by snad měla být schopna změnit názor, i když o tom silně pochybuji.
- Indexace (Indexing): Efektivní organizace paměti pro rychlé vyhledávání. Aby ta věc nemusela prohledávat celý svůj „mozek“ kvůli každé informaci, což stejně dělá.
- Zapomínání (Forgetting): Odstraňování irelevantních nebo zastaralých informací. Klíčová dovednost nejen pro umělou inteligenci, ale i pro klidný spánek člověka. Občas je zkrátka potřeba vymazat cache. I když, jak dobře víme, ono „správné“ zapomínání je někdy věda sama o sobě – jak u lidí, tak u strojů.
- Vyhledávání (Retrieval): Nalezení a vybavení relevantních informací z paměti v pravý čas. A právě tady to nejčastěji selhává.
- Komprese (Compression): Zmenšení objemu uložených informací bez ztráty podstatného obsahu. Protože i digitální prostor něco stojí, ačkoli se tváříme, že je nekonečný.
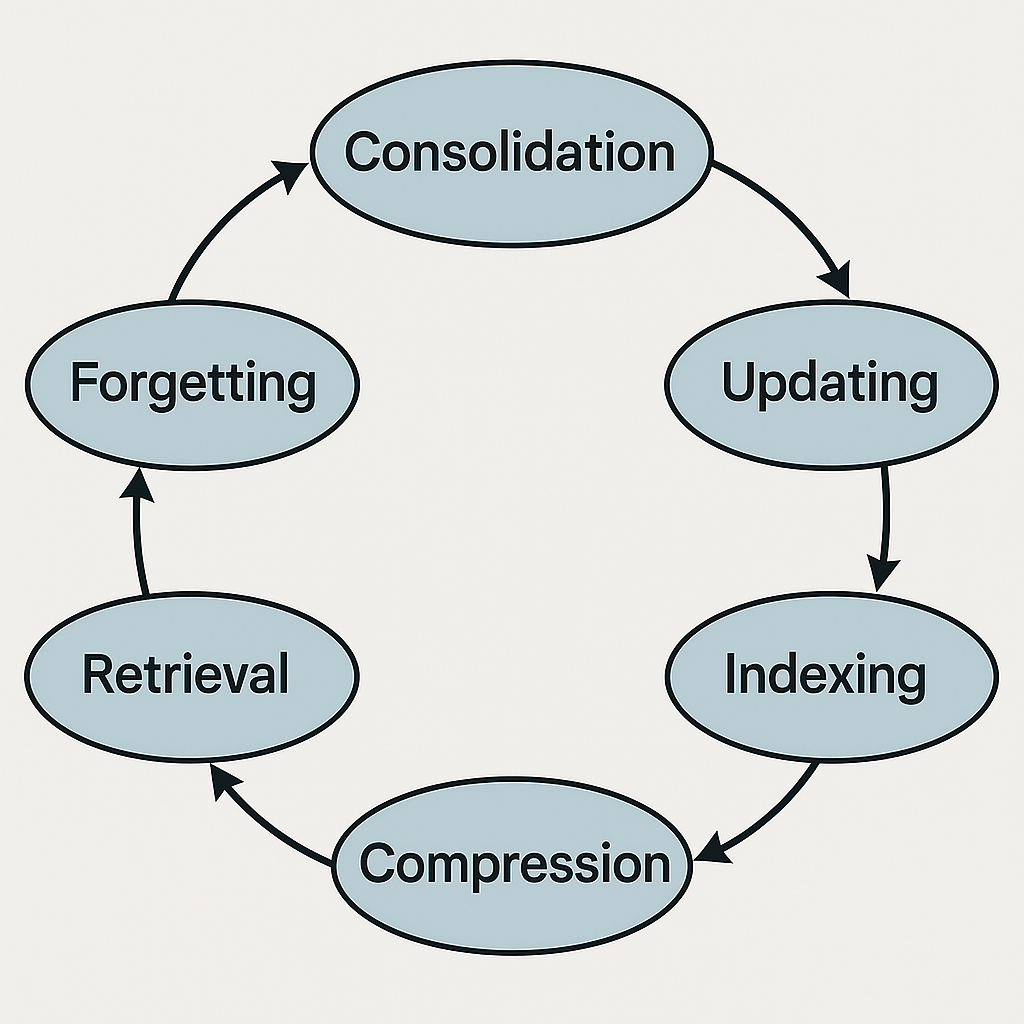
Abstraktní diagram znázorňující šest vzájemně propojených konceptů označených: Konsolidace, Aktualizace, Indexace, Zapomínání, Vyhledávání, Komprese, uspořádaných cyklicky nebo jako uzly v síti, reprezentující operace s pamětí AI, asi jako ozubená kola nějakého složitého, leč poruchového stroje. Zdroj: Vytvořeno AI generátorem
K čemu je to všechno vlastně dobré?
Tento nový pohled, tato taxonomie, není, doufejme, jen dalším akademickým cvičením pro pár nadšenců se zálibou v úhledném škatulkování a publikování impaktovaných článků. Systematické mapování těchto operací na relevantní výzkumná témata (jako je dlouhodobá paměť, práce s dlouhým kontextem, úprava parametrů modelu nebo využití více zdrojů paměti) prý poskytuje mnohem jasnější obraz o tom, jak systémy založené na LLM fungují. Tvrdí se, že to umožňuje lépe porovnávat různé přístupy, navrhovat cílenější benchmarky a vyvíjet efektivnější nástroje. Představte si, že konečně máme nejen mapu, ale i kompas pro navigaci v komplexním světě paměti umělé inteligence. Možná. A možná, jen možná, to pomůže zkrotit občasné halucinace našich digitálních společníků, i když otázkou za milion dolarů zůstává, kde přesně leží hranice mezi chybou a žádoucí, či spíše trpěnou kreativitou – máte na to snad někdo jasný názor? Obávám se, že ne.
Budoucnost paměti (a možná i nás)
Autoři studie tímto svým přehledem údajně otevírají dveře k hlubšímu pochopení a cílenějšímu vývoji paměťových systémů v umělé inteligenci. Ačkoliv se článek, jak se na vědeckou práci sluší a patří, drží odborného jazyka, nelze si nevšimnout jistého, snad až nepatřičného vzrušení z možností, které se tímto otevírají. Lepší paměť, tvrdí se, znamená chytřejší, adaptabilnější a spolehlivější umělou inteligenci. Do té doby nám, obyčejným smrtelníkům, nezbývá než doufat, že si ta umělá inteligence zapamatuje spíše naše lepší stránky, pokud nějaké máme, a spekulovat, která z těch šesti operací bude v budoucnu představovat největší výzvu – nebo naopak příležitost k dalšímu generování článků a grantů.
Bio Box – Autoři studie, protože na nich záleží, že?
Studii "Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions" zpracoval mezinárodní tým výzkumníků, jejichž jména a afiliace jsou pro úplnost uvedeny, ačkoli je otázkou, zda to někoho skutečně zajímá:
- Yiming Du: Doktorand na Čínské univerzitě v Hongkongu (CUHK), zaměřuje se na zpracování přirozeného jazyka (NLP) pod vedením Prof. Kam-Fai Wonga.
- Wenyu Huang: Postgraduální výzkumný pracovník na Univerzitě v Edinburghu v rámci doktorského programu pro NLP.
- Danna Zheng: Doktorandka na Univerzitě v Edinburghu v rámci doktorského programu pro NLP, spolupracuje s Prof. Mirellou Lapatou a Prof. Jeffem Z. Panem.
- Zhaowei Wang: Výzkumník na Hong Kong University of Science and Technology (HKUST) ve skupině Knowcomp, se zaměřením na NLP.
- Sebastien Montella: Seniorní výzkumný vědec v Huawei Edinburgh Research Center, zabývá se mj. LLM a plánováním (PDDL).
- Mirella Lapata: Profesorka NLP na Univerzitě v Edinburghu, vedoucí postava v oboru, členka Alan Turing Institute.
- Kam-Fai Wong: Profesor na CUHK, expert na čínské informační technologie, databáze a vyhledávání informací, Fellow of ACL.
- Jeff Z. Pan: Profesor na Univerzitě v Edinburghu, expert na znalostní grafy, sémantický web a AI, působí také v Poisson Lab Huawei a Alan Turing Institute.
Další čtení, kdyby snad někdo toužil po detailech
- Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions (arXiv): Původní vědecká práce, která detailně rozebírá navrženou taxonomii, operace a mapuje je na současný výzkum. Zde najdete kompletní detaily, grafy a odkazy na další relevantní studie pro případný hlubší ponor do této problematiky, kdyby vás snad přepadla taková pošetilost.
Emoce ve stroji: Mohou být generativní inteligence vtipnější než lidé?
Autor: Stanislav Mihulka (04.07.2024)
Inteligence GameNGen sní o legendární videohře Doom z roku 1993
Autor: Stanislav Mihulka (30.08.2024)
Vyzraje umělá inteligence na vyznavače konspiračních teorií?
Autor: Jaroslav Petr (14.09.2024)
Strojové učení a 3D tisk vytvořili materiál váhy polystyrenu a pevnosti oceli
Autor: Stanislav Mihulka (28.01.2025)
Rekordně zmapovaná část myšího mozku má 85 tisíc neuronů a půl milionu synapsí
Autor: Stanislav Mihulka (13.04.2025)
Duše ve stroji: Jak psychologie mění svět umělé inteligence
Autor: Viktor Lošťák (05.05.2025)
Mozky na kari: Lahlouova diagnóza kognitivního zahlcení v éře AI
Autor: Viktor Lošťák (07.05.2025)
Fyzika z křemíku: Když umělá inteligence hledá vzorečky vesmíru
Autor: Viktor Lošťák (09.05.2025)
Diskuze:


